Loading data - hands-on
This manual explains how to load data in Fabric using various notebooks for different loading methods. The following default loading notebooks are available:
- DAG \ DAG_Gold
- DAG \ DAG_LayerLoader
- Loaders \ Load_bronze
- Loaders \ Load_silver
- Loaders \ Copy_Data_Lakehouse
And there are some temporary notebooks:
- Loaders \ Load_history
- Loaders \ Object_maintenance
Each notebook includes a description in its Markdown cells. This manual focuses on the workflow and how these notebooks can be used in daily operations.
Known limitations
Keep in mind that the default options for Fabric are relatively new and sometimes limited. For example, not all options normally available for a DAG (Directed Acyclic Graph) are supported yet. As a result, in some cases, we use a simpler approach, even though a full DAG can handle more advanced tasks. We use RunMultiple to run the DAG configurations.
When opening a notebook and change the contents, it will be saved to the workspace automatically. Those changes will affect a scheduled load when there is no new deployment in between. So it's better to call the notebook from a personal notebook via a Run statement. At the end some examples are provided.
DAG LayerLoader
This is the most important notebook and can load the complete Fabric environment for a workspace (e.g., DEV, TST, PRD). In PRD, this notebook should be scheduled to load the workspace with fresh data.
The LayerLoader notebook has parameters to configure which layers (Bronze, Silver, Gold) to load. You can also use the folder_path parameter to filter objects. This only works for the Bronze and Silver layers, because Gold has nothing to do with the Objects files.
Bronze
For each load order, a DAG is created and run. It starts with the lowest load order and continues until all load orders for Bronze are complete. The tasks for Bronze call the Load_bronze notebook. You can optionally supply the skip_notebookbronze parameter to skip pre-processing steps.
Silver
The Silver part works similarly to Bronze. Each task calls the Load_silver notebook. This step only runs if the Bronze step succeeds, or if Bronze is skipped.
Gold
Gold starts the DAG_Gold notebook, providing the model.yaml configuration. If there are multiple models, you can clone the Gold box and configure it with the desired model file.
How to run a notebook without touching the original
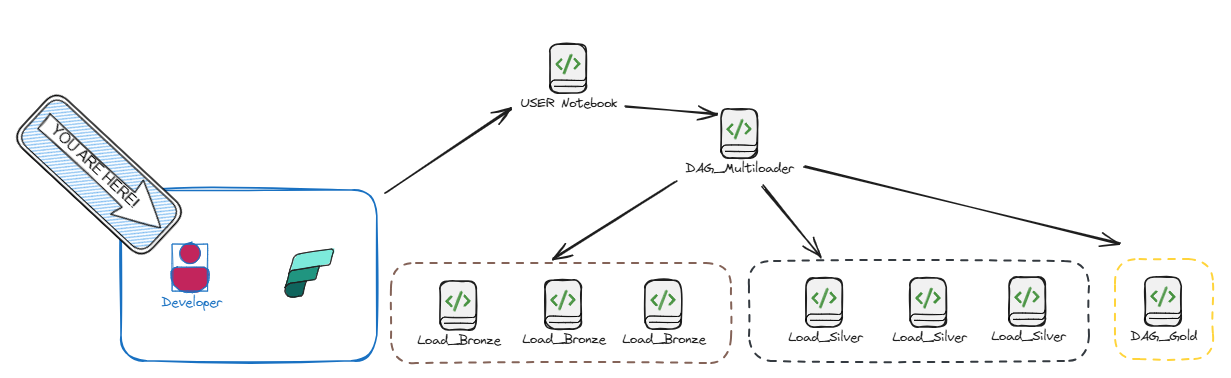
Open your own personal notebook in the User folder and use the script below to call the DAG_LayerLoader.
import json
# Configuration
folder_path = "Files/Objects"
skip_notebookprebronze = False
model_file = "Files/Model/DM/model.yaml"
layers = ["Bronze", "Silver", "Gold"]
params = {
"folder_path": json.dumps(folder_path),
"skip_notebookprebronze": json.dumps(skip_notebookprebronze),
"model_file": json.dumps(model_file),
"layers": json.dumps(layers)
}
notebookutils.notebook.run("DAG_LayerLoader", 83200, params)
Common Scenarios
Use the table below to adjust the parameters for your specific needs:
| Scenario | folder_path | layers | skip_notebookprebronze |
|---|---|---|---|
| Full Load (Default) | "Files/Objects" | ["Bronze", "Silver", "Gold"] | False |
| Bronze Only | "Files/Objects" | ["Bronze"] | False |
| Specific Object | "Files/Objects/MyTable.yaml" | ["Bronze", "Silver"] | False |
| One Source Folder | "Files/Objects/MySource" | ["Bronze"] | True |
Loading a single object with overrides
For testing or re-loading one object you can call Load_bronze directly with a small DAG, and pass overrides in the args dict to change the default validation for that run only:
object_yaml_file = "Files/Objects/AdvWorks/orders.yaml"
DAG = {
"activities": [
{
"name": "Load_bronze_1",
"path": "Load_bronze",
"timeoutPerCellInSeconds": 3600,
"args": {
"object_yaml_file": object_yaml_file,
"skip_stale_check": True, # old file, but still the correct data
"skip_prebronze": True, # don't re-run the pre-bronze notebook
"force_reload": True, # reload even if the source is unchanged
},
}
]
}
notebookutils.notebook.runMultiple(DAG)
| Override | What it does |
|---|---|
skip_prebronze | Skips the pre-bronze notebook. The data load still runs — only that hook is skipped. Useful when a pre-bronze step fetches fresh source data you don't want during a test. |
skip_midbronze | Skips the mid-bronze notebook. |
skip_postbronze | Skips the post-bronze notebook. |
skip_stale_check | Skips the stale-file validation (maxfileagehours). Use when a file is older than the window but still the data you want — e.g. an extra run after the normal schedule. An INFO line is logged. |
force_reload | Reloads even when the source files are byte-for-byte unchanged (disables skipifsourceunchanged). |
Each flag controls one thing, and they're independent — force_reload only disables the unchanged-source skip, not the stale check, so they don't conflict. All overrides default to False (omit them for normal behaviour). The hook flags above are Bronze; Load_silver accepts skip_presilver / skip_postsilver. The older skip_notebookprebronze parameter still works and maps onto skip_prebronze.